
DevOps Takes Practice: How New Relic Evolves Reliability. Matthew Flaming & Beth Adele Long at New Relic's 2017 FutureStack conference in London. youtube ![]()
YOUTUBE FX03FnvIE0g
DevOps Takes Practice: How New Relic Evolves Reliability. Matthew Flaming & Beth Adele Long at New Relic's 2017 FutureStack conference in London. youtube ![]()
Lede: devops and reliability practices empower teams to ship great software.
Origin story begins in October 2014 with a Sev1: New Relic's categorization for the most serious service disruption. "We didn't communicate well internally. We didn't drive the incident to closure as quickly as we could have. And, maybe most importantly, we weren't as transparent as we wanted to be with our customers. In the clarity of hindsight, our scale had really outstripped our processes for dealing with this type of thing. [So] our organizational reaction was coming from a place of mistrust and anxiety."
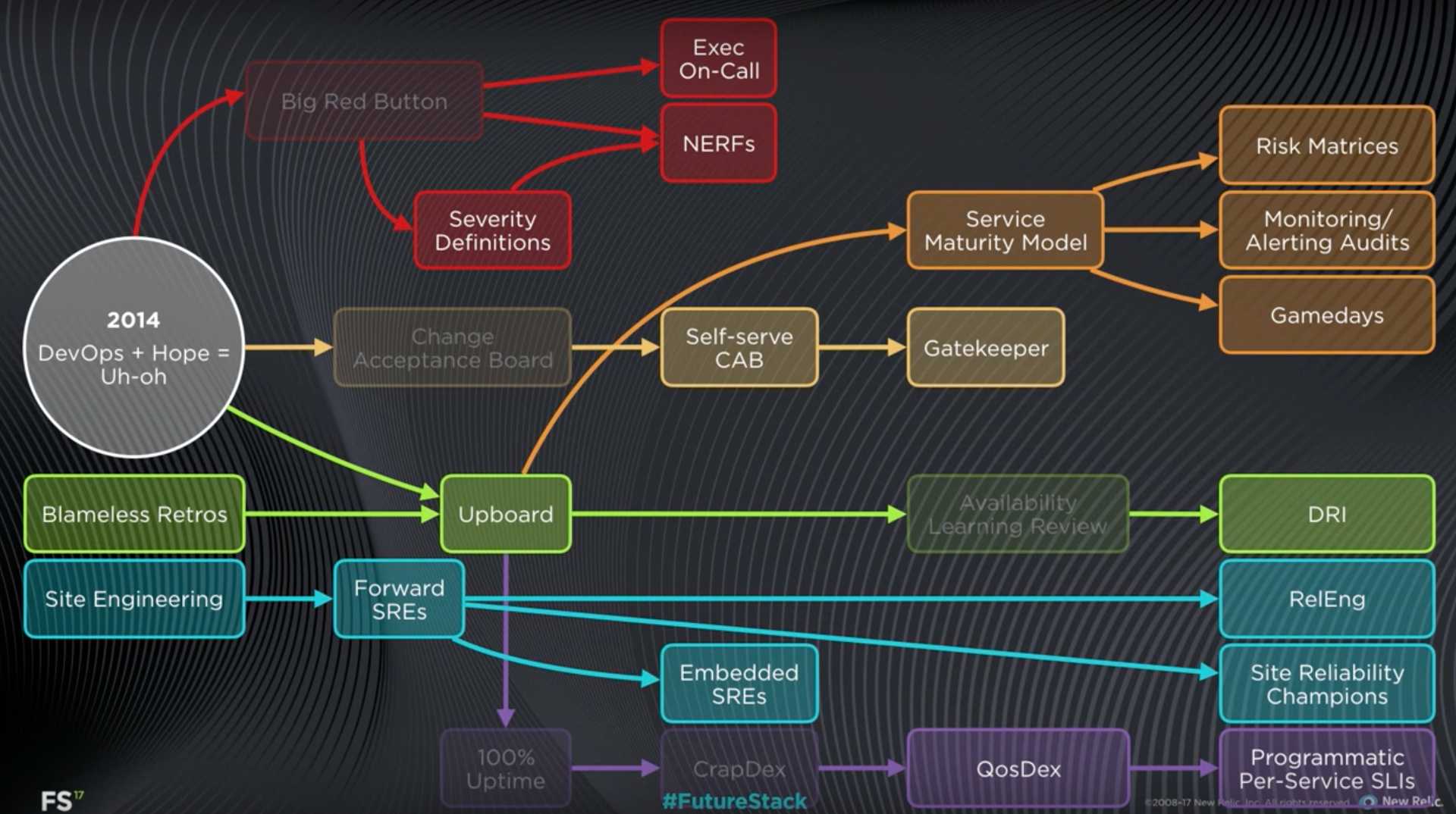
New Relic reliability evolutionary tree, 2014-2017
Insight about scale in two senses: 1) conventional measures like 300M+ requests per minute, 600M+ new data points per minute, 50B events queried per minute; 2) scale of organizational complexity, 200+ services, 4PB storage, 40+ teams, dozens of releases per week. "It's a fundamentally different problem to coordinate 10 engineers, and to coordinate 200 engineers. When we talk about our reliability processes, keep in mind they were designed to support this kind of scale: both in the sense of a serious data platform, but also working in an environment where change is happening pretty fast."
Teams. About 4-8 engineers, half software engineers and half site reliability engineers. Full-ownership to build, manage, and operate their own portfolio of services. Do their own deploys. Write their own runbooks. Organize their on-call rotations. Manage their own processes.
"We want to make sure that all of us have ... empathy for what we're delivering to our customers. If your bad code is waking someone else up at 2am, it's hard to really feel that urgency around fixing it or how it's impacting people."
Failed experiments
Change Acceptance Board (CAB). "It's useful to look at the example of our change acceptance board. In its first incarnation, this looked like going into a dimly lit room with a couple of architects and trying to convince them that your your changes were safe to release. This did, in fact, help us catch some risky releases, some potentially conflicting deploys, and maybe, most importantly, it helped teams slow down and think more conscientiously about the risk their changes might introduce. All of that's good, but, as you might imagine, [it was] not exactly popular with engineers. We also found pretty quickly that over time our releases were getting bigger and bigger as changes piled up behind the CAB. Ironically we had increased risk through the law of unintended consequences."
The Big Red Button. "There was no alternative between an engineer going it alone and calling in the infantry. So engineers were avoiding calling for help because calling for help was such a big deal."
Availability learning review process. "This was again a manual process, and, frankly, a painful one where after incidents engineers would come before a board of senior executives and technical staff and essentially confess their sins. The purpose was to learn and to hold ourselves accountable, but, as you can imagine, the more common side effect was to demoralize teams and actually discourage transparency."
Successes
Don't repeat incidents. "The DRI process that we instituted really was the key that unlocked a new era of stability for us." Jade Rubick wrote an article about New Relic's DRI work. article ![]()
Service maturity model. Risk matrix: list everything that could go wrong and estimate impact and likelihood for each. Monitoring and alerting: ensure there were monitors and alerts on each risk, and gradually reduce the risk of each. Gamedays: proactive injection of faults in production; test automation is insufficient at this scale and complexity.
NewRelic Emergency Response Force (NERFs). See Great Incident Commander
Evolution of SRE role
I mentioned that at New Relic we work in teams where software engineers and SREs are both first class members. But that wasn't always the case. Back in 2014 we did have SREs at New Relic, but they mostly lived in a couple of centralized teams in site engineering. The problem there was our SREs weren't engaging proactively with teams around reliability issues. Instead teams had to come to them and have to wait in line to get their needs met.
Our first evolution was moving to the model of forward SREs. In that model an SRE would work with a given team for a per period of typically a few months to help that team with their tooling, their processes, and then rotate onto another team. This is this is an improvement, but the problem here is that when that SRE moved on, the team might be left with process and tooling they didn't fully understand and wouldn't necessarily be ready to tackle the next challenge that came up with them.
We iterated the organization again to where we are today: embedded SREs. Now SREs are first class members of their teams. They don't rotate between teams. There are a lot of benefits to this. There's long-term alignment and skin in the game for the work that the SREs do. They have an opportunity to become domain experts in the software that team is building and operating. And they have an opportunity to mentor other members of the team and help them grow the SRE skill set. So we're growing our collection of SREs all the time. This is great for empowering teams to do good work.